Jingjing Chen
2023.1 - present
|
I am a fourth-year Ph.D. student @ Computer Science in Wu Wenjun Honorable Class, Shanghai Jiao Tong University (SJTU) and Shanghai Artificial Intelligence Laboratory, advised by Prof. Cewu Lu. Previously, I got my B. Eng. degree @ Computer Science and Engineering, and B. Ec. degree @ Finance from SJTU in 2022. I'm expected to graduate in 2027. |

Photo @ Port Campbell, Australia 🇦🇺 (2026) |
|
|
* denotes equal contribution. # denotes corresponding author(s).
Filter by topic:
|
|

|
arXiv 2026
We propose a latency-aware guidance fusion framework for asynchronous multimodal diffusion policy composition. It allows modality-specific policies to operate at their native inference rates and contribute denoising guidance whenever available. To make asynchronous composition consistent, we derive a reference-frame rebasing rule for diffusion variables under relative action representations, enabling delayed guidance to be aligned before fusion. |

|
arXiv 2026
We propose AnyDexRT, a calibration-free retargeting method for intuitive dexterous teleoperation across human-like hands. AnyDexRT combines self-supervised fingertip correspondence learning with few-shot human guidance to anchor the mapping in task-relevant regions, and further refines pinch-related poses using a contact classifier. |
|
|
RSS 2026
We introduce a physically grounded interaction frame that decouples motion and force control axis from demonstrations. By combining a global vision policy and a high-frequency local policy with hybrid force-position control, Force Policy improves contact stability, force regulation, and generalization on real contact-rich tasks. |

|
ECCV 2026
We introduce ChronoFlow, a temporally unified representation that captures past, current, and future interaction dynamics through sparse 3D keypoints of both objects and the gripper. Built on this representation, ChronoFlow-Policy is a diffusion-based visuomotor policy that jointly learns ChronoFlow and action sequences through a co-training objective. |

|
IROS 2026
LIDEA transfers human demonstrations through dual-stage 2D feature distillation and embodiment-agnostic 3D geometry alignment. This cross-embodiment design makes human-to-robot imitation more reliable and improves generalization to new setups. |

|
arXiv 2026
We introduce X-Imitator, a versatile dual-path framework that models spatial perception and action execution as a tightly coupled bidirectional loop, enabling continuous mutual refinement between spatial reasoning and action generation. |
|
|
ICRA 2026
We introduce an object-centric history representation built upon point tracks, compressing long-horizon observations into task-relevant object memory for diverse visuomotor policies. This efficient design consistently outperforms both Markovian and prior history-based baselines, improving decision quality and task success. |
|
|
ICRA 2026
DQ-RISE quantizes dexterous hand states and couples them with arm diffusion through a continuous relaxation for structured arm-hand learning. This balances the action space and yields more efficient learning in dexterous manipulation. |

|
arXiv 2025
We introduce AnyDexGrasp, a data-efficient dexterous grasping method that transfers across different robotic hands, built upon the intermediate contact-centric grasp representations. It achieves high real-world success in cluttered scenes with over 150 novel objects, demonstrating scalable cross-hand grasp generalization. |
|
|
CoRL 2025
Oral
We develop AirExo-2 for low-cost, large-scale in-the-wild collection and convert human demonstrations into pseudo-robot data. Together with the generalizable visuomotor policy RISE-2 that integrates 3D perception and 2D visual foundation models, this pipeline reaches strong performance without teleoperated data. |

|
IROS 2025
We formulate object-centric knowledge as a semantic keypoint graph template, and use a coarse-to-fine matching strategy to inject them into policy learning. This design improves category-level abstraction and boosts generalization across objects. |

|
IROS 2025
We propose modal-level exploration to generate diverse multi-modal interaction data, then learn from the most informative trials and segments. This self-improvement loop raises data efficiency and steadily strengthens policy capability over time. |
 |
ICCV 2025
We propose a bidirectionally expanded action head that unfolds action sequences in a coarse-to-fine manner. This design preserves the capability of policy backbone while enabling logarithmic-time inference for faster manipulation control. |
|
|
RA-L 2025
&
IROS 2025
FoAR is a force-aware policy that fuses vision with high-frequency force/torque sensing using a future-contact-guided gating module. This enables phase-adaptive control and delivers more accurate, robust contact-rich manipulation. |
|
|
RA-L 2025
&
ICRA 2026
MBA is a plug-and-play module that cascades action diffusion for object motion generation and motion-guided robot action generation. Integrated into existing policies, it consistently improves manipulation performance in various tasks. |
 |
ICRA 2025
CAGE is a data-efficient generalizable policy utilizing visual foundation models and causal attention. With 50 demonstrations in a single domain, it generalizes to unseen backgrounds, objects, and viewpoints while outperforming prior methods. |

|
ICRA 2025
S2I is a segment-level selection and optimization framework for mixed-quality demonstrations that plugs into existing policies. Using only a few expert references, it improves downstream performance and makes suboptimal data more usable. |

|
IROS 2024
RISE is an end-to-end imitation policy that predicts continuous actions directly from single-view point clouds. With only 50 demonstrations per task, it outperforms representative 2D and 3D baselines in accuracy, efficiency and generalization. |
|
|
ICRA 2024
Best Paper
We contribute Open X-Embodiment, a 1M+ trajectory real-robot dataset spanning 22 embodiments, plus large RT-X models trained at scale. This breadth enables strong cross-embodiment co-training gains and advances robotic foundation models. |
|
|
ICRA 2024
AirExo is a low-cost portable dual-arm exoskeleton for joint-level teleoperation and in-the-wild demonstration collection. Pre-training with scalable in-the-wild data improves sample efficiency and robustness. |
|
|
ICRA 2024
RH20T is a real-world dataset of 110k+ sequences across diverse skills, robots, viewpoints, and contexts with synchronized visual, force, audio, tactile, and action signals. Its scale and multimodal quality make it a great training source for one-shot and generalizable manipulation. |
 |
IROS 2023
We propose a flexible handover framework with real-time robust grasp-trajectory generation and future grasp prediction. This improves adaptability to dynamic handover scenes and raises success on moving-object grasps. |
|
|
CVPR 2023
We reformulate reactive grasping around target-referenced semantic consistency rather than only temporal smoothness. Tracking in generated grasp spaces improves grasp reliability for dynamic objects. |
|
|
T-RO 2023
&
ICRA 2024
AnyGrasp is a unified model for static and dynamic general grasping that predicts accurate dense full-DoF grasps efficiently. It remains robust under severe depth noise, improving real-world deployment reliability. |
|
|
RA-L 2022
&
ICRA 2023
TransCG is a large-scale real-world transparent object depth completion benchmark. We also propose a lightweight baseline DFNet for depth completion of transparent objects. This closes a key sensing gap and improves perception for transparent objects. |
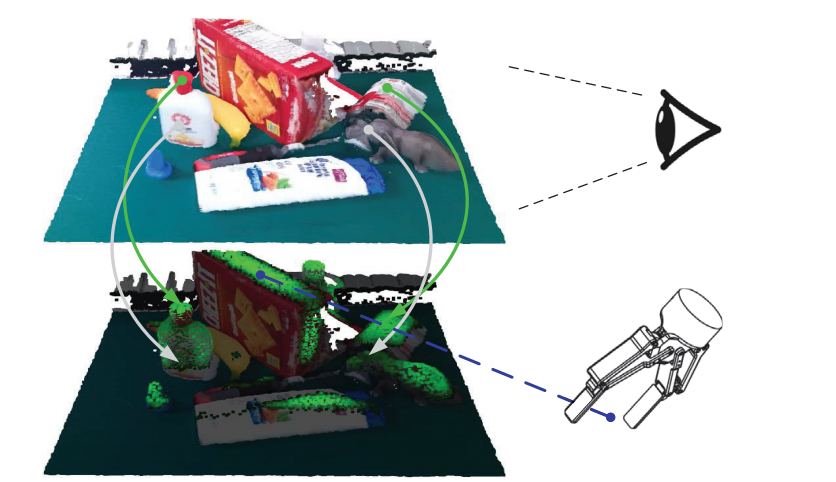
|
ICCV 2021
We propose graspness, a geometry-driven grasp quality measure for identifying graspable regions in clutter via look-ahead search. A learned graspness predictor enables fast, accurate grasp detection in practice. |
|
|
|

|
research project
Provides an easy and unified interface for robots, grippers, sensors and pedals. |
|
course project of SJTU undergraduate course "Mobile Internet"
Proposes that we can learn "jargons" like "ResNet" and "YOLO" from academic paper citation information, and such citation information can be regarded as the searching results of the corresponding "jargon". For example, when searching "ResNet", the engine should return the "Deep Residual Learning for Image Recognition", instead of the papers that contains word "ResNet" in their titles, as current scholar search engines commonly return. |
|
|
Reviewer for Conferences :
Reviewer for Journals :
|
|
|
|
I collaborate closely with Hao-Shu Fang @ UMD, Chenxi Wang @ Noematrix, Shangning Xia @ Noematrix, Lixin Yang @ SJTU, Shirun Tang @ Noematrix, Jun Lv @ Noematrix and Shiquan Wang @ Flexiv. I welcome opportunities for discussions and potential collaborations, and I am particularly interested in working with highly motivated undergraduate and master's students. Please feel free to contact me via email. I'm fortunate to work with the following students: Current students6
Zihao He
2024.3 - present
Ying Feng
2025.3 - present
Haoxiang Qin
2025.12 - present
Junjian Hu
2026.5 - present
Yuetong Ding
2026.6 - present
Previous students4
Yunhan Guo
2024.12 - 2025.6
Xiyan Yi
2025.1 - 2026.6
Yinong He
2025.5 - 2025.9
Mingyu Mei
2025.8 - 2026.3
|
|
Beyond research, I am a passionate traveler who loves immersing myself in new experiences. From chasing skylines and tasting diverse cuisines to meeting locals, I document my journey through photography. Click a country to see the world through my lens.
0
Countries
0
Continents
0
Cities
0
Photos
Loading world map…
drag spin · scroll zoom · click a highlighted country for photos/details
Continent:
No countries match this filter yet. |
|
I share some of my notes in the courses I took at graduate school in this page. More notes during my undergraduate study can be found in this repository. |